

This week I got to attend SAS Innovate on Tour in both Frankfurt, Germany and Madrid, Spain. At both Agentic AI was the number on topic. The questions and discussions were really deep and I can not wait until we get into building our own agents in this newsletter, but we will continue with building a strong foundation, before we charge into the latest topics.
News
To me this week again showed Google flexing its muscles when it comes to AI with three notable releases:
Top of mind is of course the release of Gemini 2.5 Pro. The model is very impressive, but not yet available in the Free Tier, so we will be sticking with the Flash model for now.
Next up is the open-source release of MedGemma. This model is specifically tuned towards medical image task and build so that it can be easily fine-tuned.
And finally Google makes GPU available as a Cloud Run option, meaning you can now pay-per-second for GPU time, using scale-to-zero and minimal warm up times.
Articles/Papers
This is a great introduction to help think about when fine-tuning can make sense.
And here we have a blog post about the unreliablity of LLMs, how to take that into account and building around/on top of it. I think this one is especially valuable for anyone building with AI.
Rounding things out this week is this paper that investigates when Large Reasoning Models actually boost task performance and when they fail. The part that sticks out to me is that there is no enhancement for low complexity tasks so you can safe on tokens and thus time + money.
Deep Dive
As teased in last weeks edition we will now take a look at the results from the LLM and gain an understanding what we see there. As always this is also available as a YouTube video here.
I took the JSON response from last weeks call and display it here below:
{
"candidates": [
{
"content": {
"parts": [
{
"text": "Okay, imagine you ... [Cut off for readability]"
}
],
"role": "model"
},
"finishReason": "STOP",
"avgLogprobs": -0.2837159293038504
}
],
"usageMetadata": {
"promptTokenCount": 36,
"candidatesTokenCount": 56,
"totalTokenCount": 92,
"promptTokensDetails": [{ "modality": "TEXT", "tokenCount": 36 }],
"candidatesTokensDetails": [{ "modality": "TEXT", "tokenCount": 56 }]
},
"modelVersion": "gemini-2.0-flash",
"responseId": "n7NFaI_EO-qH1PIPnaKMqA4"
}
When we look at this result we see four top level entries:
candidates
useageMetadata
modelVersion
responseId
Let’s take a look at each one of them in detail.
Candidates
This entry contains the actual model response, meaning here we see the answer for which we prompted the model. It can be found under content > parts > text - the text part is relevant because Gemini models are also capable to respond with other types of outputs like images.
On the same level as the part is also the role - this one indicates that this is a response generated by a model. This is included in order to facilitate easier multi-turn conversations, i.e. chats, where you add all the previous responses back into the next call and flag what came from the user and what was generated by the model.
Now we find ourselves at the finish_reason this indicates what lead the model to decide why it responded. The most common response you will see is STOP, which indicates that the model as reached a stopping point or sequence and thus stopped to generate additional tokens. There is a lot of other reasons for a response a finished response that can be related to exciding the number of tokens in a request or triggering a safety mechanism - for a list of them take a look a the Google documentation.
The avgerage log probability indicates the numerical measure of how confident the model is in its produced output. A avgLogprops of around 0 indicates a very high confident. Between -1 and -2 it indicates a fairly confident output and below -2 it indicates a very low confidence in the generated answer.
Usage Metadata
Here we get information about how many tokens were used in the call. This is important as tokens are what is being used to calculate the costs of an API request (if we weren’t on the free tier) and it is also important to track it, in order to not hit the context length of a model which would lead to the finish_reason to change.
The promptTokenCount details how many input tokens we sent to the model - a million input tokens cost $0.10 and the candidatesTokenCount details how many tokens the model responded with - a million output tokens cost $0.40. The pricing information was retrieved from here. From my response that would mean this request cost us $0.0000036 + $0.0000224 = $0.000026 - if it weren’t for the free tier.
The totalTokenCount is exactly what it says it is. And the promptTokenDetails & candidateTokenDetails enable you to further break the tokens down once we do multi-modal requests to the model.
Model Version & Response ID
The modelVersion is very straight forward just re-iterating which model was used for the generation of this request. The responseId is unique for each generated response for the model and is mainly used for diagnostic or support cases to help identify/share bugs with the Google Cloud support.
Updating our Code
Again we will take the previous weeks code, and enhance the code to more nicely display the response data we get from the LLM in order to maximize the impact that we can have. For this I have again provided SAS and Python code to walk through this.
The goal of this section is to display the actual textual response of the model, next the amount of input and output tokens, check the average log probability to ensure that we communicate the confidence in the answer and we check the finishing reasoning.
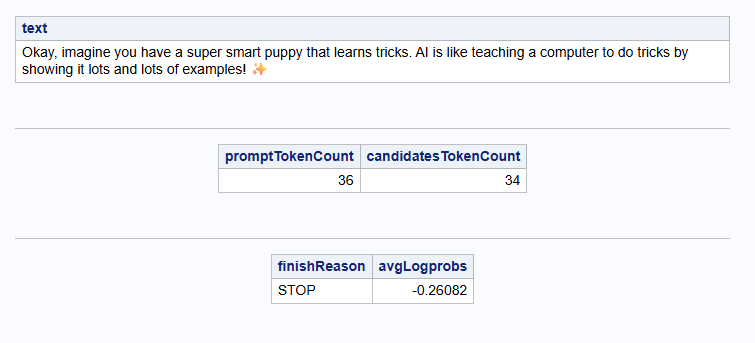
The final output in Python looks like this:
Okay, imagine you have a really smart puppy who learns by seeing lots and lots of pictures and hearing lots and lots of words. AI is kind of like that puppy!
**AI learns by looking at lots of things and then tries to guess what comes next!**
Input Tokens: 36
Output Tokens: 55
Answer Confidence: high
Finish Reason: STOPAnd in SAS it looks like this:
See you next week, when we will dig more into how we can change the request itself.