


AI Field Notes
AI News and Practical Deep Dive: 4th of August - 10th of August 2025

Already the 10th edition of the AI Field Notes, time really flies. In the deep dive section we have already achieved quite a bit from our initial key setup to now having a function in place to help iterate faster and even talking a look at an embedding model last week. With this great foundation in place we set off this week to start a new face exploration.
News
This week was clearly dominated by OpenAI with their two big releases but other important things happened as well:
Maybe the biggest model introduction was Genie 3 by Google. This world model showcases an incredible dynamic and consistent simulation approach. Watching the videos is really showcasing what is possible. Sadly there currently is no general access to try it out and test how good it could for for Synthetic Data generation.
GPT-5 the long awaited is here and it has clearly focused on code. During the livestream 90%+ of what they talked about was its coding ability, most likely to recapture the developr audience that had shifted towards Claude Code. The model is really good, but far from the leap that was initially teased back at the end of 2024.
OpenAI releases two open-weight models (gpt-oss) that are on par with some other leading open-weight models, with the smaller variant fitting on to M3 MacBooks.
Only small news because of the incredible week is the release of Claude Opus 4.1, that pushed up all of Claude Opus 4 already impressive benchmarks by a couple of percentage points. And the Qwen team released Qwen3-4B-Thinking-2507 which is a small, yet highly capable reasoning open-weight reasoning model.
Articles
Not necessarily an article but the new response format that OpenAI has applied for its open-weight models is really fascinating with its ideas around output channels and structering. Definitly worth a read, if you are thinking about working with these models.
LLMs need to keep the first few tokens of a conversation, known as attention sinks, in memory. This is because the softmax function forces the model to put its attention somewhere, and it learns to park unused attention on these initial tokens.
This paper by Anthropic explores the concept of persona vectors, which are internal model directions corresponding to personality traits. These vectors can be used to monitor a model's personality, steer its behavior to amplify or suppress traits, and even predict which training data will cause undesirable personality shifts before finetuning.
Deep Dive
In todays edition we will be creating our own simple evaluation benchmark and run tests on it. If you are just starting with this series please check out this resource to guide you through previous editions.
For this first evaluation we will be doing a simple question and answering benchmark were we pose multiple choice questions, ask the LLM to only answer with the choice it thinks is correct and than evaluate based off that.
As a first step we will create a new dataset folder in which we store any datasets from here on so that it is easy to reuse them as well. In there we create a simple csv file with three columns:
question, the actual question we want to be asking
choices, a list of choices that we will request the LLM to chose its answer from
answer, the letter of the multiple choice with the correct answer
Here are the ten questions that I chose and that are available as part of the GitHub repository:
What is the capital of France?,a)Paris;b)London;c)Berlin,a
What is the largest planet in our solar system?,a)Earth;b)Mars;c)Jupiter;d)Saturn,c
Which country is known as the Land of the Rising Sun?,a)China;b)Japan;c)South Korea;d)Vietnam,b
What is the chemical symbol for water?,a)H2O;b)CO2;c)O2,a
What is the smallest country in the world?,a)Vatican City;b)Monaco;c)San Marino,a
What is the main ingredient in guacamole?,a)Avocado;b)Tomato;c)Onion,a
What is the hardest natural substance on Earth?,a)Iron;b)Gold;c)Diamond,c
What is the largest mammal?,a)Elephant;b)Blue Whale;c)Giraffe,b
What is the capital of Japan?,a)Seoul;b)Tokyo;c)Osaka;d)Beijing,b
What is the primary language spoken in Brazil?,a)Spanish;b)Portuguese;c)English;d)French,bAll pretty simple general knowledge question, so the expectation is that the LLM will be really good at answering these.
So let’s get to coding where we start of with copying over the code we have written from the foundation piece - either Python or SAS. If you are using the Python version make sure to use pip install pandas, as we require this additional package.
Next we need a good system prompt to run this - feel free to tweak this one:
'You are an expert in general knowledge question multiple choice answers. You will be given a question with multiple choice answers. You will answer the question with the correct answer, by only returning the letter of the correct answer. If you do not know the answer, provide a 1.'There is one additional thing now that we are testing for and it is called prompt adherence. We are asking the LLM to only respond with the answer letter or a 1 if it doesn’t know the answer. Let’s see how consistent the LLM is with its work. By the way would you like to see more concept like prompt adhesion to be explained in more depth?
Next we import our dataset and that call the LLM function once for each question where we insert the question + choices as the userPrompt and store the answers.
Check out the SAS and Python code to see how it turned out, but simply you just call the function in a loop for each one and is an example output:
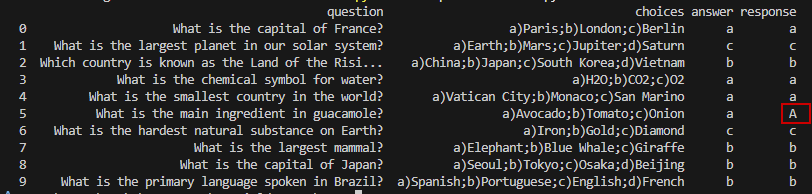
The answers are all correct, but interesting on the fifth question the LLM responded with a capital A instead of a lowercase a - that might be because of the A in avacado being capitalized. We can of course go back to adjusting our system prompt in order to specify that it should only respond with lowercase answer keys or when we create a comparison function we make sure to do that.
This behavior was pretty consistent for me, sometimes even providing a upper case letter for different answers as well. So all in all I would give the LLM (I left the gemini-2.5-flash-lite default LLM) a 10/10 score for the general knowledge test and a 9.5/10 for prompt adherence.
What is your experience with this simple first evaluation test?